Bases de datos paralelas
Sistemas paralelos
Los sistemas paralelos utilizan varias CPU y discos que son capaces de ejecutar operaciones en paralelo.
Desde el punto de vista de las bases de datos, un sistema paralelo busca mejorar el tiempo de respuesta ante consultas de usuarios.
En los sistemas paralelos podemos distinguir dos tipos:
Máquinas paralelas de grano grueso: Pocos procesadores y muy potentes.
Máquinas paralelas de grano fino: Muchos procesadores de potencia limitada.
La utilización de bases de datos paralelas buscan aumentar:
Productividad: Refleja el número de tareas que pueden realizarse en un intervalo de tiempo determinado.
Tiempo de respuesta: Tiempo necesario para completar una única tarea y ofrecer una respuesta.
Ventajas y desventajas del uso de bases de datos paralelas
Ventajas:
Ganancia de velocidad.
Ampliabilidad: aumenta el número de transacciones a realizar de forma concurrente.
Desventajas:
Costes de inicio y mantenimiento.
Interferencia: como se comparten recursos, como la memoria, pueden aparecer retrasos por la competencia en el uso de estos.
Sesgo: Normalmente las tareas no se dividen en tamaños idénticos, con lo que siempre habrá tareas más pesadas o largas que otras.
Arquitecturas paralelas
Memoria compartida
La memoria se comparte para todos los procesadores.
La principal ventaja de esta arquitectura es la comunicación directa que existe entre los procesadores. Sin embargo, la vía de comunicación se puede convertir en su principal desventaja, ya que, si existe un alto tráfico de información, la espera de cada procesador aumenta significativamente. Por ello, los procesadores que se utilizan en esta arquitectura suelen tener una memoria caché mayor.
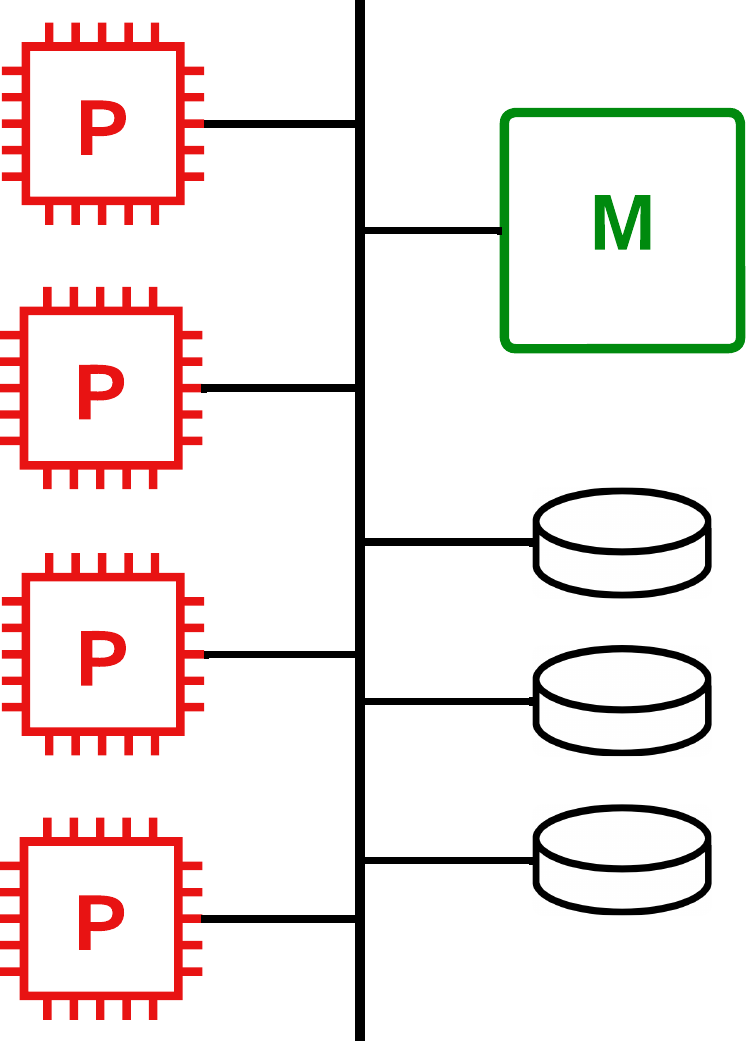
Disco compartido
Todos los procesadores pueden acceder directamente a todos los discos del sistema, eliminando así los problemas de acceso a memoria, pues cada procesador tiene su propia memoria.
Las principales ventajas de esta arquitectura son:
La vía de comunicación no se sobrecarga tanto como en la arquitectura de memoria compartida.
Mejora limitada de la tolerancia a fallos, pues podemos configurar los discos en RAID.
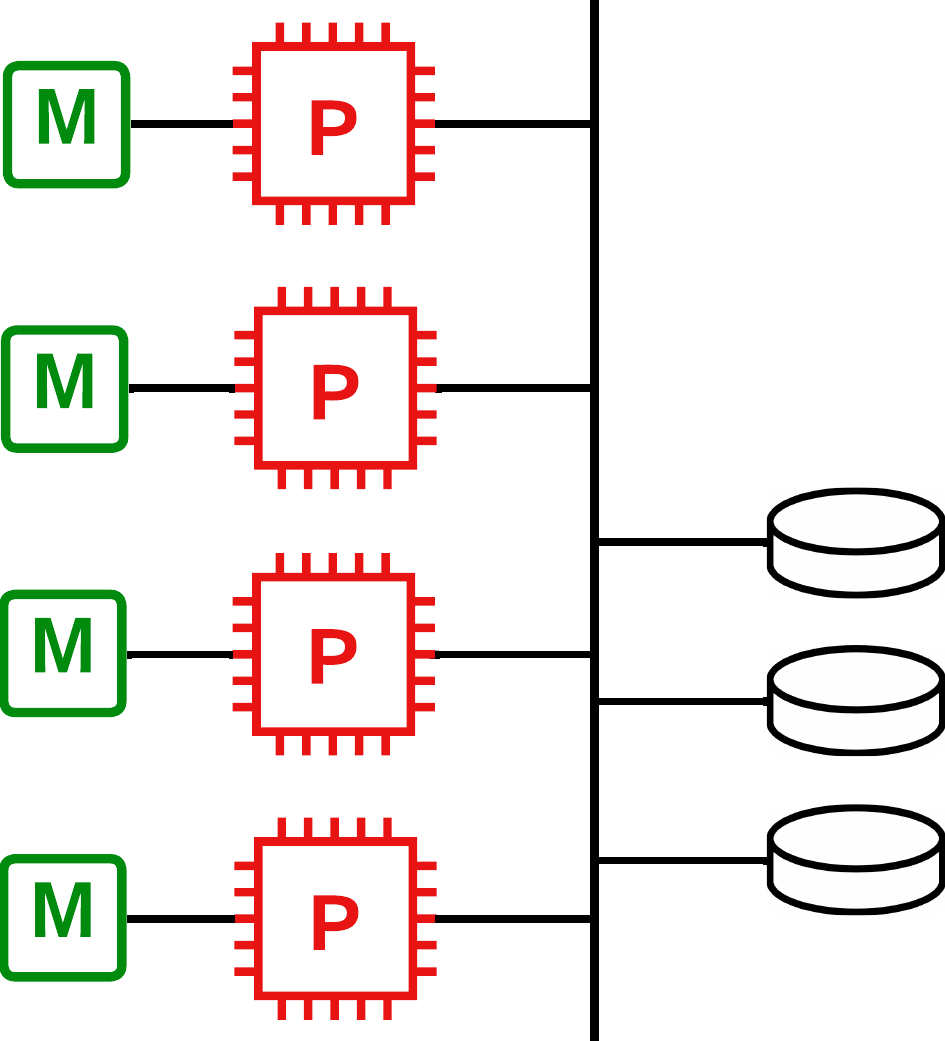
Sin compartimiento
No se comparte ni la memoria ni el disco. Cada nodo dispone de su propia memoria y de uno o varios discos.
Esta arquitectura es más ampliable y puede incorporar un mayor número de procesadores, sin embargo, el coste de comunicación y acceso a discos remotos es mayor.
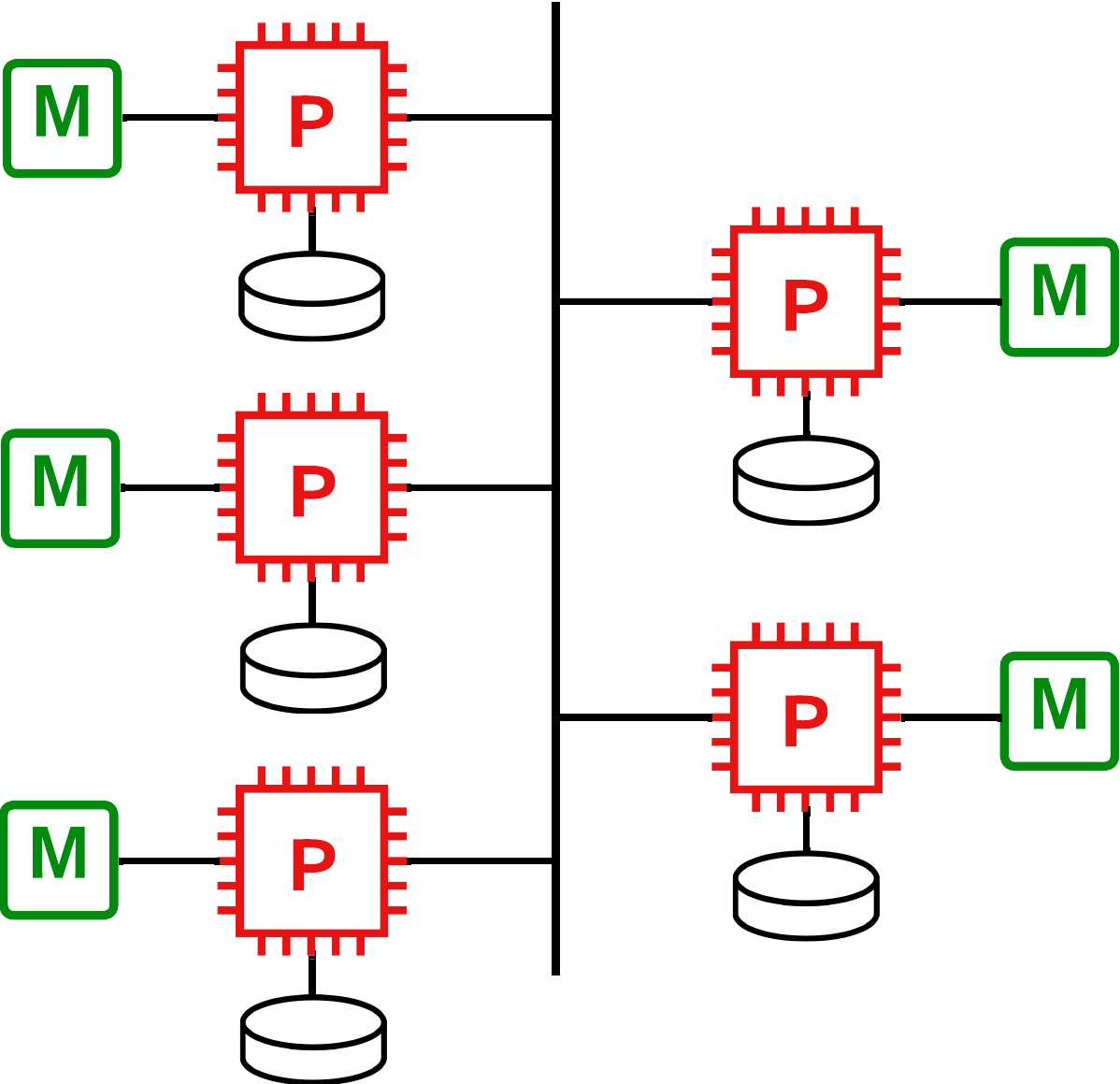
Jerárquico
Es una solución combinada de las anteriores.
Tipos de paralelismos
Paralelismo en consultas
Hablamos de paralelismo en consultas cuando una consulta se ejecuta en paralelo en diferentes procesadores.
La ejecución de una consulta en paralelo puede llevarse a cabo mediante dos alternativas que se pueden combinar:
Paralelismo en operaciones: consiste en ejecutar en paralelo las operaciones.
Paralelismo entre operaciones: se trata de ejecutar en paralelo cada una de las operaciones.
Paralelismo entre consultas
El paralelismo entre consultas se refiere a la ejecución en paralelo de varias consultas.
El tiempo de transacción es el mismo, pero incrementa la productividad. Buscamos hacer más en el mismo tiempo.
Al tratarse de lecturas en paralelo, hay que asegurarse de que la lectura de los datos se realiza sobre una copia válida de los mismos, pues pueden haber sido modificados por otras operaciones. Este problema se conoce como coherencia de cachés y afecta a todos los sistemas paralelos, no solo a bases de datos paralelas.